Context Creation Service
What it does
The Crawler solution automates the discovery and extraction of content from websites at scale. It navigates through pages, follows links, handles pagination, and pulls structured data — turning the unstructured web into clean, queryable datasets ready for analysis or integration into your existing systems.
Built in Python with configurable scraping pipelines, the crawler respects rate limits and robots.txt rules while maximising coverage. Extracted data is parsed, deduplicated, and delivered in your preferred format — JSON, CSV, or direct database insertion.
Typical use cases include competitor price monitoring, content aggregation, lead generation, market research, and feeding downstream AI pipelines with fresh, real-world data.
Architecture
Click image to enlarge
Configurable Pipelines
Custom crawl rules per domain — depth limits, URL filters, content selectors, and output schemas tailored to your target.
Scalable & Resilient
Handles thousands of pages with retry logic, proxy rotation, and session management to avoid blocks.
Structured Output
Data delivered clean — JSON, CSV, or direct to a database — ready for immediate use in dashboards or ML pipelines.
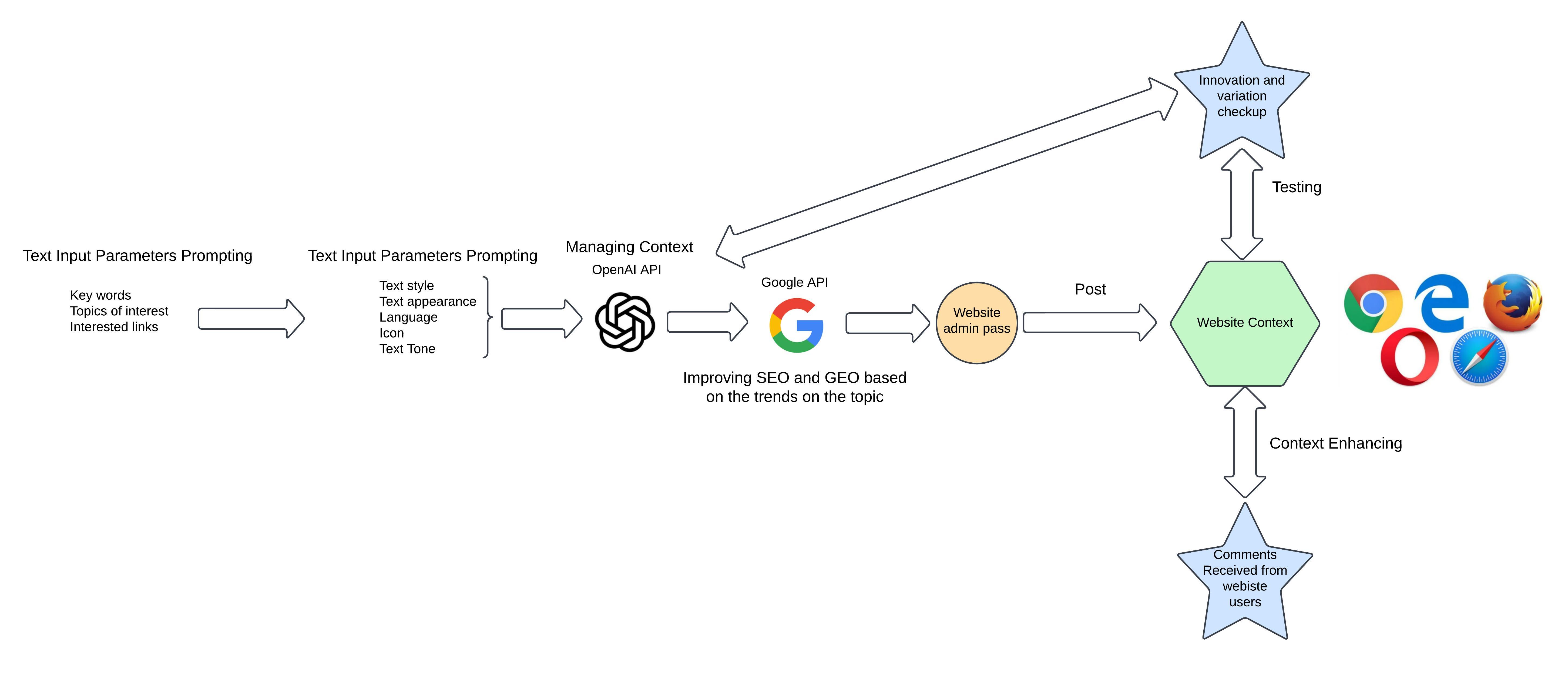
An AI-Driven Pipeline for Automated Content Generation and SEO Optimisation
When it comes to creating content for a website, generative AI can help partly, since the major part should still be conducted by human agents. This section depicts a systematic approach to creating content for a website using an AI-powered crawler pipeline.
The system consists of several components, code, and APIs to communicate with different platforms. However, the main part is the prompt, where we instruct the GPT model on how to create the content and with which parameters.
The Prompt — Core of the Pipeline
The following shows a snapshot of the prompt used for content creation:
Write a practical guide in {lang} about {gathered_content}{domain_specific_prompt}.
Include step-by-step explanations and real-world applications. Write entirely in {lang}.
Limit to {token_limit} tokens.
The words in the brackets could be static or dynamically change each time the program runs. Keywords can span domains such as robotics, aviation, computer science, and more.
SEO and GEO Ranking with Google Trends
The software is not just for creating content, but also for ranking it higher in SEO and GEO, which is why we have the Google API component. After the prompt, the text is compared against popular terms in Google Trends to produce comparable content that achieves a higher ranking.
This step is important because it shows that the purpose of the software is not just to create content, but to enhance it in a way that improves its standing in Google indexing.
Input Parameters and Configuration
A set of input parameters defines how the content should be created. This is not the final solution and could be changed based on users' ideas and content creators. They might come up with more or fewer input parameters depending on their domain expertise or creative preferences.
One of the other important components is reading the input parameters from a website location like a settings or context parameters page — this way users and clients can put their ideas and thoughts on how to create the next content, giving each piece high diversity and a unique style.
Automated Publishing
As the software becomes more sophisticated, one of the main challenges is automating the posting of content to any website once it is ready. This is done programmatically and automatically using Python. The complete pipeline creates content in a hybrid manner — managed and handled by both bots and humans — from prompt generation and Google Trends ranking through to automated publishing.
Need data extracted from the web for your project?
Get in touch